GeoRTNet : Geometric Perception based Efficient Text Recognition
| #Deep Learning #Computer Vision #Model Optimization #Pytorch
Abstract
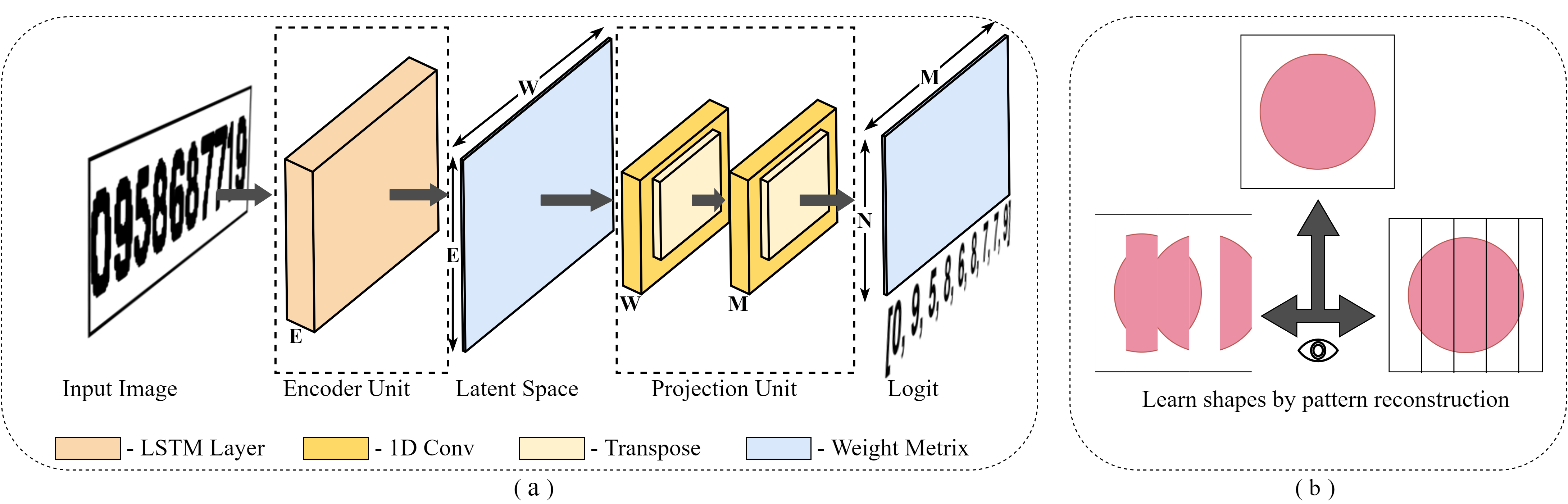
Every Scene Text Recognition (STR) task consists of text localization & text recognition as the prominent sub-tasks. However, in real-world applications with fixed camera positions such as equipment monitor reading, image-based data entry, and printed document data extraction, the underlying data tends to be regular scene text. Hence, in these tasks, the use of generic, bulky models comes up with significant disadvantages compared to customized, efficient models in terms of model deployability, data privacy & model reliability. Therefore, this paper introduces the underlying concepts, theory, implementation, and experiment results to develop models, which are highly specialized for the task itself, to achieve not only the SOTA performance but also to have minimal model weights, shorter inference time, and high model reliability. We introduce a novel deep learning architecture (GeoTRNet), trained to identify digits in a regular scene image, only using the geometrical features present, mimicking human perception over text recognition.
Key Contributions
- Novel Image Feature Encoding
- Spatial Attention Mechanism
- Fully-Convolutional multi-class multi-Label Prediction
- Synthetic Data Generation
Lessons Learned
- Geometry-Centric Approach
- Innovative Label Prediction
- Data Diversity
- Empirical Validation